D703 生活言談資料集
摘要:
我們通過那些由眾人在兩個不同時間寫的關於現實生活事件的故事,並比較兩次敘述的差異,來創建此資料集。
版本:0
說明
當回想人生經歷時,人們經常會忘記或混淆生活事件,這就需要資訊回憶的服務。因此我們構建了生活言談(NIR)資料集,該資料集對個故事,提供2個不同時間點(pre-retold and post-retold)的敘述差異,並請人標註。
NIR
Introduction
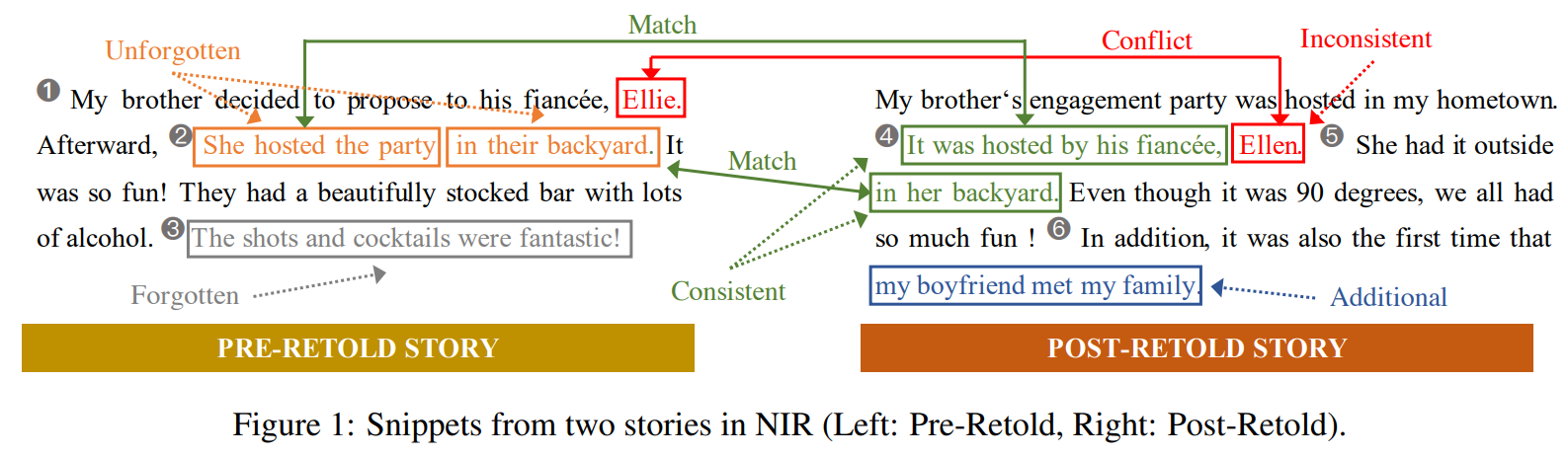
Hippocorpus is constructed for investigating the difference in the narrative flow between relating life experiences and telling imaginative stories. We construct NIR by pruning the imaginative stories in Hippocorpus and retaining those stories about real-life events written by crowdworkers at two different times as pre-retold stories and post-retold stories. We summarize the following five event types from the story pairs in the dataset: Consistent, Inconsistent, Additional, Forgotten, and Unforgotten.
Schematic diagram
Format
Each object of the JSON files is consisted of event_id(i.e., object key), pair_id, story_type, subject, predicate, object, time, event_type, and the support evidences of the event.
Example
{
"59": {
"pair_id": "3P4RDNWND6SXR9D7TBY1P0EI0KHJIR",
"story_type": "post-retold",
"explicitness": "explicit",
"subject_token_ids": [
24,
25,
26,
27,
28,
29,
30
],
"predicate": null,
"predicate_token_ids": [
31,
32,
33
],
"object_token_ids": [
35
],
"time_token_ids": [],
"event_type": "additional",
"supports": []
},
...
}
Steps
1. Download the corpus–Hippocorpus
Since we construct our dataset–NIR by exteding the Hippocorpus, we need to download the hippocorpus first.
- Go to http://aka.ms/hippocorpus
- Login your Microsoft accouot.
- Download
hippoCorpusV2.csvand save it to the parent directory(i.e.data/).
2. Download NIR dataset & Hippocorpus correction file
gdown https://drive.google.com/uc?id=13F_9A8Z1jL9Eg4IwtRospfec7HQnubOC -O ../NIR.json
gdown https://drive.google.com/uc?id=1kaViqs9FDzArV_e8F7i7TZfeoEKkpRnc -O ../errors.csv
3. Download spacy model
We use spacy tok tokenize the stories. Thus, we need to download the spacy model.
python -m spacy download en_core_web_sm
4. Tokenize the Stories in Hippocorpus
Since we only release the annotation that uses the tokenized result of the Hippocorpus, we provide the script for tokenization and preprocessing to ensure the result is the same as ours.
python tokenize_hippocorpus.py
5. Merge NIR and Hippocorpus
After parsing the Hipporcorpus, we also provide the script to merge the hippocorpus and the NIR for convenience.
python merge.py
主要檔案下載位置:
https://github.com/ntunlplab/SEEN
發表文獻:
You-En Lin, An-Zi Yen, Hen-Hsen Huang and Hsin-Hsi Chen, “SEEN: Structured Event Enhancement Network for Explainable Need Detection of Information Recall Assistance,” The 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022), December 2022.
開發團隊
臺大自然語言處理實驗室數據說明
Format
Each object of the JSON files is consisted of event_id(i.e., object key), pair_id, story_type, subject, predicate, object, time, event_type, and the support evidences of the event.
Example
{
"59": {
"pair_id": "3P4RDNWND6SXR9D7TBY1P0EI0KHJIR",
"story_type": "post-retold",
"explicitness": "explicit",
"subject_token_ids": [
24,
25,
26,
27,
28,
29,
30
],
"predicate": null,
"predicate_token_ids": [
31,
32,
33
],
"object_token_ids": [
35
],
"time_token_ids": [],
"event_type": "additional",
"supports": []
},
...
}
| 欄位名稱 | 說明 |
| pair_id | 文章配對 ID |
| story_type | 事件來源文章之類型 |
| explicitness | 事件是否是顯性 |
| subject_token_ids | 主詞詞序 |
| predicate | 謂詞 |
| predicate_token_ids | 謂詞詞序 |
| object_token_ids | 受詞次序 |
| time_token_ids | 時間詞序 |
| event_type | 事件類型 |
| supports | 關聯事件代號 |
Annotation
規範文件清單
請填入個人資料以進行下載或授權申請